Given a list of thousands of patterns and a text string, how fast can you find matches in the text?
This is the problem you need to solve if you want do basic robot-traffic filtering in real time using a list of known robots and browsers. We did this at Chartbeat as part of the many requirements for receiving accreditation by Media Rating Council (MRC), an independent body that is responsible for setting and implementing measurement standards. They let everyone know that our metrics are valid, reliable, and effective. Specifically during this process, we looked at how robot/browser traffic real-time filtering was implemented using Aho-Corasick string matching, and how to modify the algorithm to deal with exception patterns.
What Counts as Robot Traffic?
Every month the Interactive Advertising Bureau (IAB) an organization that sets standards for the online ads industry, releases a list of known robots and browsers with string matching rules, which when applied to a user agent string of an HTTP request, decides if the request is from a robot or a browser. Some string-matching rules only apply at the beginning of the UA string and others anywhere within the string. Also, some patterns have exceptions like ‘bigbot’ is a robot string except if it’s a substring of ‘bigbottle’ or ‘bluebigbottle’.
The MRC requires our metrics to be 100% clean of robot traffic, following the guidelines set by the IAB. We require it of ourselves too.
Filtering Traffic in Real Time
Our real-time metrics are computed by memoryfly, a custom in-memory data store that receives pings (HTTP GET requests) from people viewing content on the web.
This traffic regularly peaks past 250K requests/second.
Before filtering for robot traffic, memoryfly only looked at User-Agent (UA) strings to count how many people are on mobile, tablet, or desktop devices. With a growing list of robot patterns — to potentially thousands of patterns — and the high throughput of requests, it’s best to keep the user-agent processing time down.
So, for this work, our goal was to keep the user agent string processing to O(n + M) time, where n is the length of the UA string and M is number of robot/browser patterns.

String Matching
There are many known string matching algorithms, and a good number that can match in O(n) time. Most string matching algorithms preprocess the pattern once and built up a data structure that makes future lookups fast. Knuth-Morris-Pratt (KMP) does this using a partial match table that is built early on by preprocessing the pattern string. The table tells you where the next place to go once a mismatch occurs and you never move backwards in the text string. Using KMP or any other single pattern matching linear time algorithm, the runtime would be O(n * M). With a small number of patterns this would be ok, but it’s questionable when we have hundreds and potentially thousands of patterns to match against.
Here’s a KMP failure table for the pattern ”bobobotbot”
Pattern : b | o | b | o | b | o | t | b | o | t
-----------------------------------------------
Failure : 0 | 0 | 1 | 2 | 3 | 4 | 0 | 1 | 2 | 0
Prefix trees

Some of the robot/browser matching rules count a match only at the beginning of the UA string – a prefix match. A prefix tree or trie of patterns would be perfect for this case, having UA string match runtime of O(n + M) time matching against multiple patterns. But most of the robot pattern rules didn’t fit this (less than 5% of robot patterns were prefix matches only).
Aho-Corasick
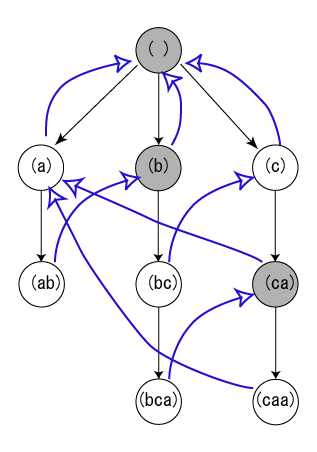
Aho-Corasick is a multi-pattern string matching algorithm that runs in O(n + M) time. It’s kind of a combination of using a prefix tree and KMP. It uses a state machine containing the patterns, and runs the text string through the state machine in a single pass to find any matches.
- The state machine consists of states, and goto and failure transitions.
- The states and goto transitions/edges are the same as a prefix tree.
- The failure transitions/edges tell you what state to go to next in order to continue matching.
- These failure edges help skip unnecessary character match attempts based on the current state of the automaton.
Like KMP, you never move backwards for matches and the state machine’s transition table of failure and goto edges act like KMP’s partial match table, which tells you where the next best place to go once a mismatch occurs. KMP is equivalent to AC using a single pattern.
Goto edges are just prefix tree edges, where the current character in the text matches a character in a pattern. A failure edge of any state s, is an edge to state t, such that the string that represents the path from the start state to t is the longest prefix that is also the suffix of the string that represents the path from the start state to s. Like with patterns “fasten” and “astor”:
[0] -'f'- [1] -'a'- [2] -'s'- [3] -'t'- [4] -'e'- [5] -'n'- [6]
| //
| //
| //
| //
| //
|- -'a'- [7] -'s'- [8] -'t'- [9] -'o'- [10] -'r'- [11]
After matching “fast”, but failing to match the ‘e’, you can jump to state right after the ‘t’ in astor and continue from there.
find(pattern_state_machine, text_string)
{
current_state = pattern_state_machine.start
list matches
foreach current_letter in text_string {
// look for a trie edge we can continue
// matching along
while(current_state.goto[current_letter] == NULL) {
// failure state transition
current_state = current_state.failure
}
// make the goto state transition
current_state = current_state.goto[current_letter]
// if there are any matches at this state,
// add them to the list
if current_state.matches
matches.add(current_state.matches)
}
return matches
}
Okay, there are two nested loops, how is the runtime linear? The state machine at any point makes either a goto transition or a failure transition. When matching a substring of the text against the pattern set, a goto transition will move the substring end forward by one and a failure transition will move the substring start forward by at least one. The outer for-loop iterates the goto transitions and the inner while-loop iterates failure transitions. Since there are no backwards moves when matching the text string, the number of goto and failure transitions are each at most n, where n is the length of the text string, making the total number of transitions 2n.
Did I lose you? It helps to look at this example:
With these robot patterns: “bot”, “otis”, “ott”, “otto”, and “tea”, we get this prefix tree representing the state machine containing patterns with just goto edges.
[0] -'b'- [1] -'o'- [2] -'t'- [3]
|
| --'o'- [4] -'t'- [5] -'i'- [6] -'s'- [7]
| |
| | --'t'- [8] -'o'- [9]
|
| --'t'- [10] -'e'- [11] -'a'- [12]
The failure edges are defined by this function f of type state -> state.
f 2 = 4
f 3 = 5
f 5 = 10
f 8 = 10
f 9 = 4
f _ = 0
Running the text string ”botttea” through the state machine we go through these transitions:
state text output
0 []botttea
1 [b]otttea
2 [bo]tttea
3 [bot]ttea bot
5 b[ot]ttea
8 b[ott]tea ott
10 bot[t]tea
0 bott[]tea
10 bott[t]ea
11 bott[te]a
12 bott[tea] tea
In each transition above, the substring within the brackets is the current match candidate. You can see how neither bracket moves backwards. The resulting matched patterns are “bot”, “ott”, and “tea”.
Handling Pattern Exceptions
The IAB robot/browser lists had some pattern matching rules with exceptions:
pattern | exceptions
------------------------------
bo | bottle, robot
tle | bottle
irob |
The string “irobottles”, matches “irob”, “bot”, and “tle”, but also exceptions “bottle”, and “robot”. “bot”, and “tle” get canceled out by its exceptions, but “irob” is left, which makes “irobottles” a robot match.
To be fair, this seems like a very specific and probably rare case, but it does happen.
The original Aho-Corasick algorithm outputs all matched patterns. So if the state machine contains exception strings, they will be returned too.
To handle the exception patterns, we can change the above algorithm to return only a set of maximal pattern matches, so we avoid returning pattern matches that are substrings of other patterns. The above rules matched with text string “irobottles” will return matches “irob”, “robot”, and “bottle”, leaving out “bot” and “tle”. This helps with exception patterns because matched exception patterns will cover their substring robot/browser patterns. Then we can filter out the matches that are exception strings, to only leave valid robot pattern matches, like “irob”.
find_maximal(pattern_state_machine, text_string)
{
current_state = pattern_state_machine.start
list matches
longest_match
foreach current_letter in text_string {
while(current_state.goto[current_letter] == NULL) {
// after failing a goto, output our current
// longest match. the current longest match
// cannot be a substring of the next match
// by definition of failure. our next valid
// goto'd state represents at most a proper
// suffix of the prefix representing our
// current state.
if (longest_match) {
matches.add(longest_match)
longest_match = NULL
}
// failure state transition
current_state = current_state.failure
}
// make the goto state transition
current_state = current_state.goto[current_letter]
// if a pattern ends at this state, the last
// pattern we saved is a substring of it so it's
// ok to overwrite since it follows a goto.
if (current_state.is_end_of_pattern)
longest_match = current_state.pattern
}
// we may have saved the last pattern at the end
if (longest_match)
matches.add(longest_match)
return matches
}
The longest match saved is the full pattern represented by that state, ignoring substring pattern matches because they’re not maximal. The longest match is saved on successive goto transitions and then added to the list of results once the automaton makes a failure transition, since there’s no way for the next longest match to be a superstring of the current one. Iteration over the text string is unchanged, so the runtime remains linear.
The original Aho and Corasick paper, Efficient string matching: an aid to bibliographic search, goes into more details about how to build the failure table, a few formal proofs, and some further optimizations. But hopefully this gives you a rundown of how we practically do the same in real time.
We found our overall robot traffic to be only about 0.3%, which is pretty great news. Our numbers are not skewed by robot traffic and the robots haven’t taken over…yet.
Please feel free to share thoughts and ideas, especially if you have your own solutions to this kind of problem — would be great to hear and learn from what you’ve learned.
